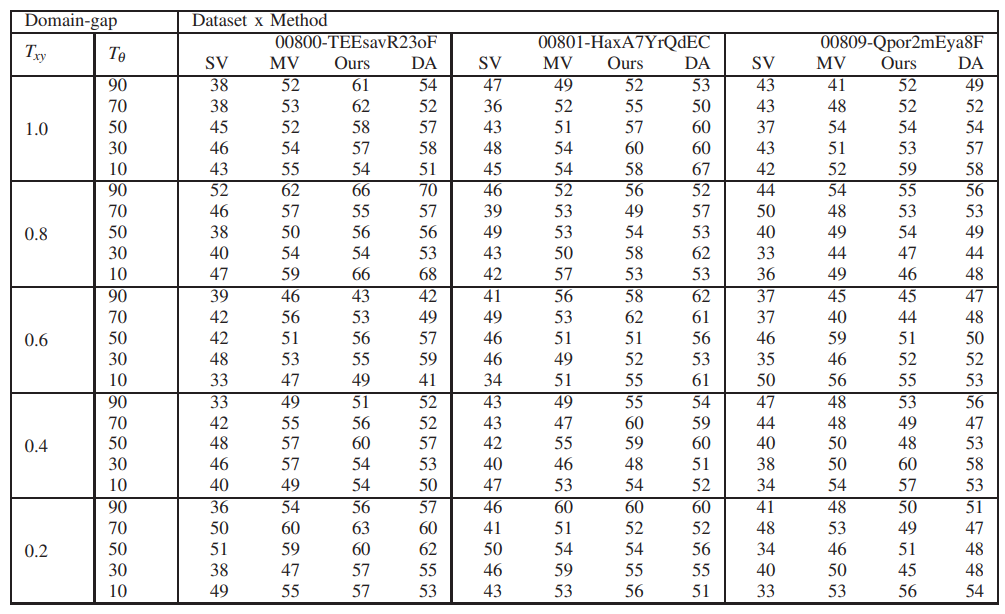
Fig. 1. Our framework generates a scenegraph, embeds it, and transfers it to the active planner.
Semantic localization, i.e., robot self-localization with semantic image modality, is critical in recently emerging embodied AI applications (e.g., point-goal navigation, object- goal navigation, vision language navigation) and topological mapping applications (e.g., graph neural SLAM, ego-centric topological map). However, most existing works on semantic localization focus on passive vision tasks without viewpoint planning, or rely on additional rich modalities (e.g., depth measurements). Thus, the problem is largely unsolved. In this work, we explore a lightweight, entirely CPU-based, domain-adaptive semantic localization framework, called graph neural localizer. Our approach is inspired by two recently emerging technologies: (1) Scene graph, which combines the viewpoint- and appearance- invariance of local and global features; (2) Graph neural network, which enables direct learn- ing/recognition of graph data (i.e., non-vector data). Specifically, a graph convolutional neural network is first trained as a scene graph classifier for passive vision, and then its knowledge is transferred to a reinforcement-learning planner for active vision. Experiments on two scenarios, self-supervised learning and unsupervised domain adaptation, using a photo-realistic Habitat simulator validate the effectiveness of the proposed method.
Fig. 1. Our framework generates a scenegraph, embeds it, and transfers it to the active planner.
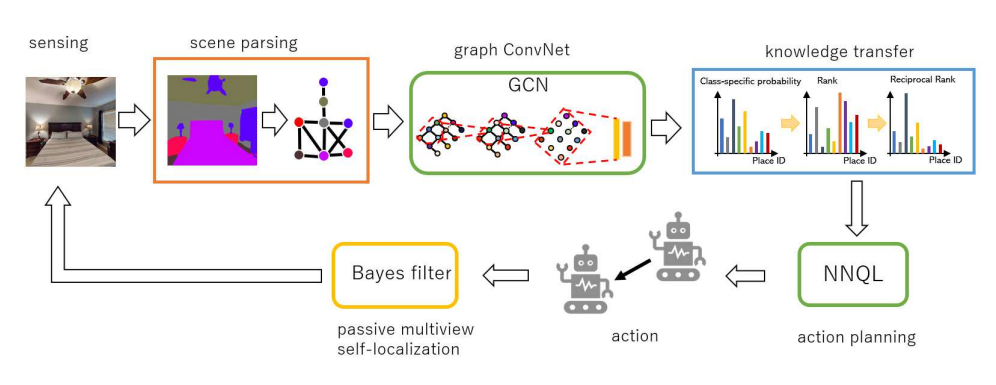
Fig. 2. Semantic scene graph.

Fig. 3. The robot workspaces and examples images for “00800- TEEsavR23oF,” “00801-HaxA7YrQdEC,” and “00809-Qpor2mEya8F” datasets.

Fig. 4. Examples of view sequences. Left and right panels show successful and unsuccessful cases of self-localization, respectively.
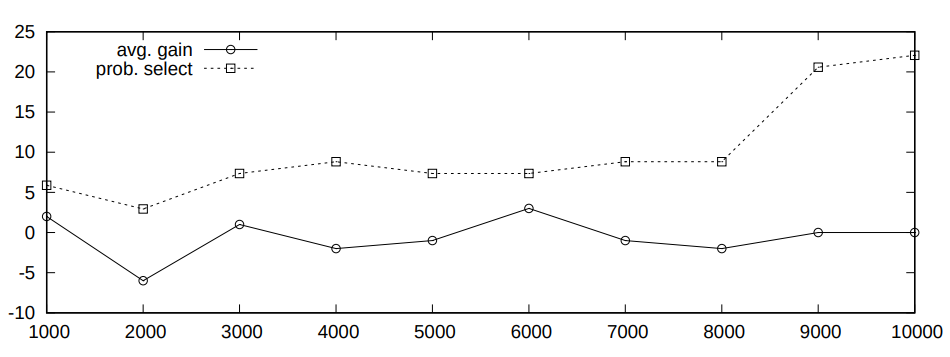
Fig. 5. Results in unsupervised domain adaptation (UDA) applications.
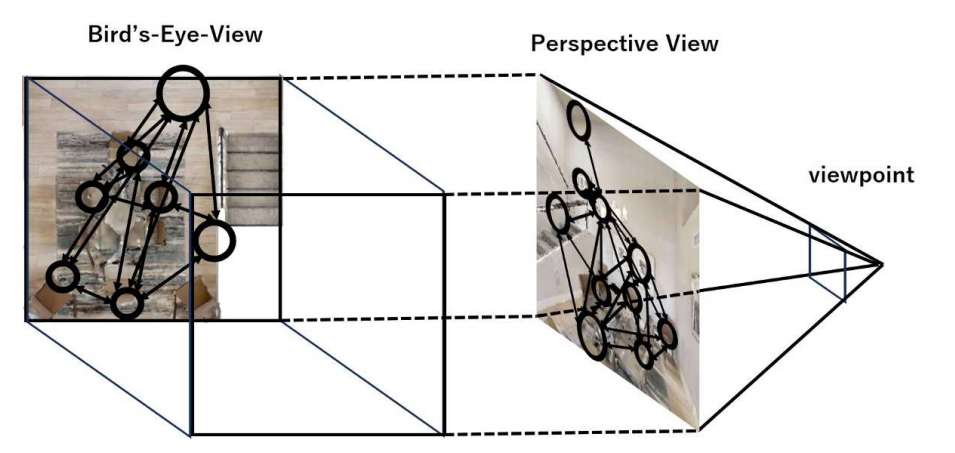
Fig. 6. Topological navigation using ego-centric topological maps. Left: Conventional world-centric map. Right: The proposed ego-centric map.
Table1:PERFORMANCE RESULTS.