Mining Visual Phrases for Long-Term Visual SLAM
Tanaka Kanji, Chokushi Yuuto, Ando Masatoshi
Keywords
Abstract
We propose a discriminative and compact scene descriptor for single-view place recognition that facilitates long-term visual SLAM in familiar, semi-dynamic and partially changing environments. In contrast to popular bag-ofwords scene descriptors, which rely on a library of vector quantized visual features, our proposed scene descriptor is based on a library of raw image data (such as an available visual experience, images shared by other colleague robots, and publicly available image data on the web) and directly mine it to find visual phrases (VPs) that discriminatively and compactly explain an input query / database image. Our mining approach is motivated by recent success in the field of common pattern discovery—specifically mining of common visual patterns among scenes—and requires only a single library of raw images that can be acquired at different time or day. Experimental results show that even though our scene descriptor is significantly more compact than conventional descriptors it has a relatively higher recognition performance.
Related document
BibTeX
@inproceedings{DBLP:conf/iros/TanakaCA14,
author = {Kanji Tanaka and
Yuuto Chokushi and
Masatoshi Ando},
title = {Mining visual phrases for long-term visual {SLAM}},
booktitle = {2014 {IEEE/RSJ} International Conference on Intelligent Robots and
Systems, {IROS} 2014, Chicago, IL, USA, September 14-18, 2014},
pages = {136--142},
publisher = {{IEEE}},
year = {2014},
url = {https://doi.org/10.1109/IROS.2014.6942552},
doi = {10.1109/IROS.2014.6942552},
timestamp = {Mon, 25 Sep 2023 20:37:18 +0200},
biburl = {https://dblp.org/rec/conf/iros/TanakaCA14.bib},
bibsource = {dblp computer science bibliography, https://dblp.org}
}
図表・写真
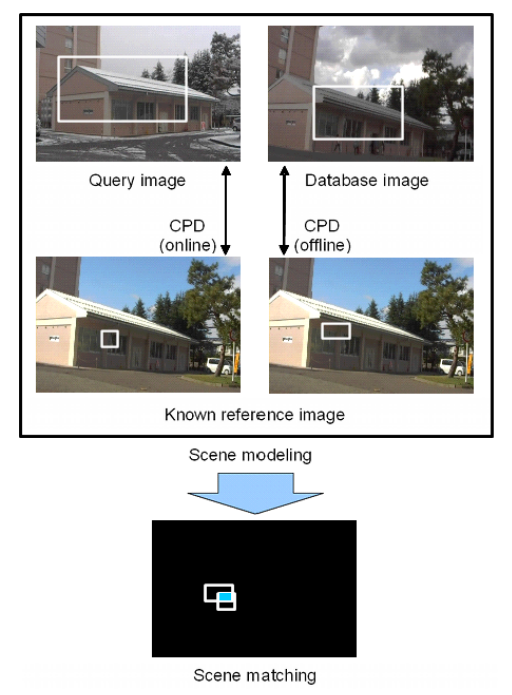
Fig. 1. Modeling and matching a pair of scene images (“query”, “database”) using our scene descriptor. A raw image matching process (“CPD”)
mines an available visual experience (“known reference image”) to find discriminative visual phrases that effectively explain an input query / database image.
The scene matching problem then becomes one of comparing reference image ID and bounding boxes between query and database scenes.
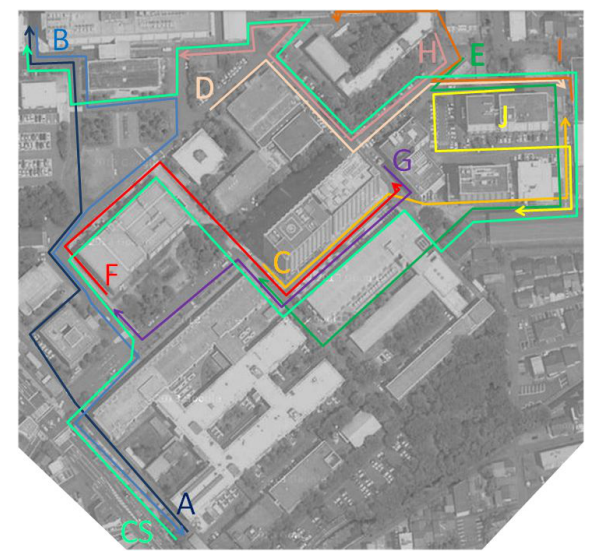
Fig. 2. Experimental environments and viewpoint paths (Bird’s eye view). a,b,c,d,e,f,g,h,i,j:
10 paths used for quantitative evaluation. CS: path used for the “cross season” case.

Fig. 3. Samples of view images used for evaluation.

Fig. 4. Examples of common pattern discovery (CPD). s1-4: The single season case. c1-4: The “cross season” case. For each panel,
the top row shows CPD for a query image and the bottom row shows CPD for the ground truth database image. For each panel, the left
column shows the input image, the middle column shows the reference image selected for CPD, and the right column shows the CPD results, i.e., voting map and BB.
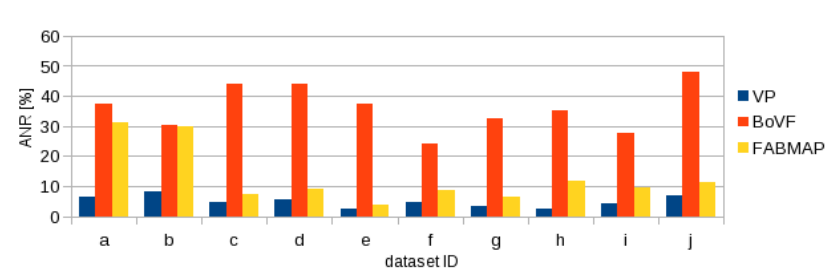
Fig. 5. Quantitative performance.
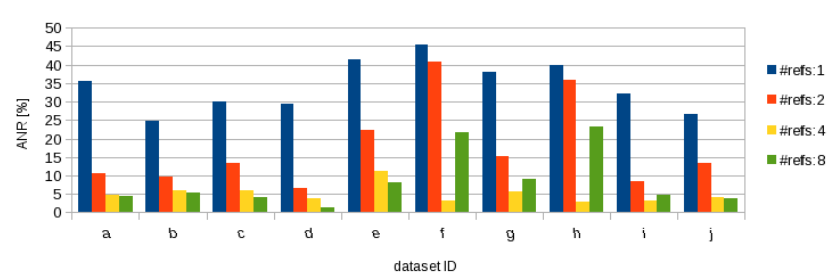
Fig. 6. Results for various #reference images.
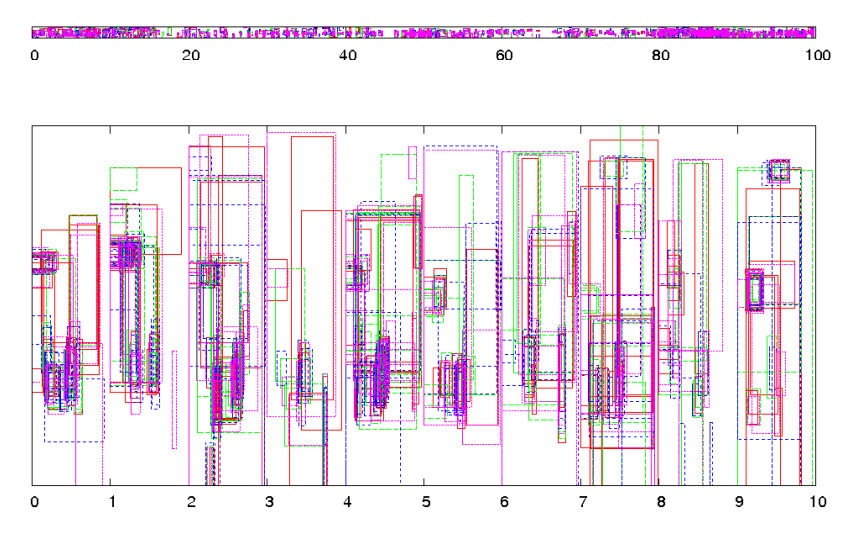
Fig. 7. Selected reference images and their bounding boxes. Top: BBs for reference images. For visualization, the BB for each n-th reference image
is normalized to fit within an area [n − 1,n]×[0,1]. Bottom: x10 close-up for x ∈ [0,10].
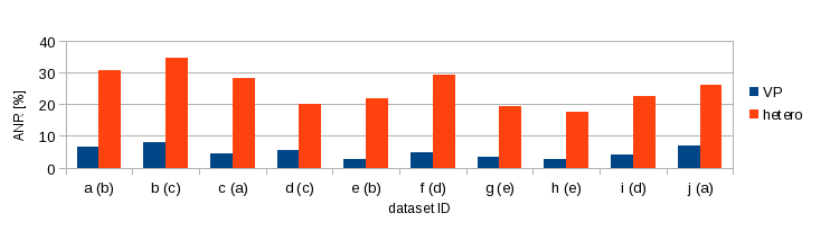
Fig. 8. Sensitivity of retrieval performance to the choice of library. The five libraries (a)-(e) are used to explain two different sets of query and database images.
“hetero”: performance when using the library from different viewpoint path. (·) indicates the path ID of the library.
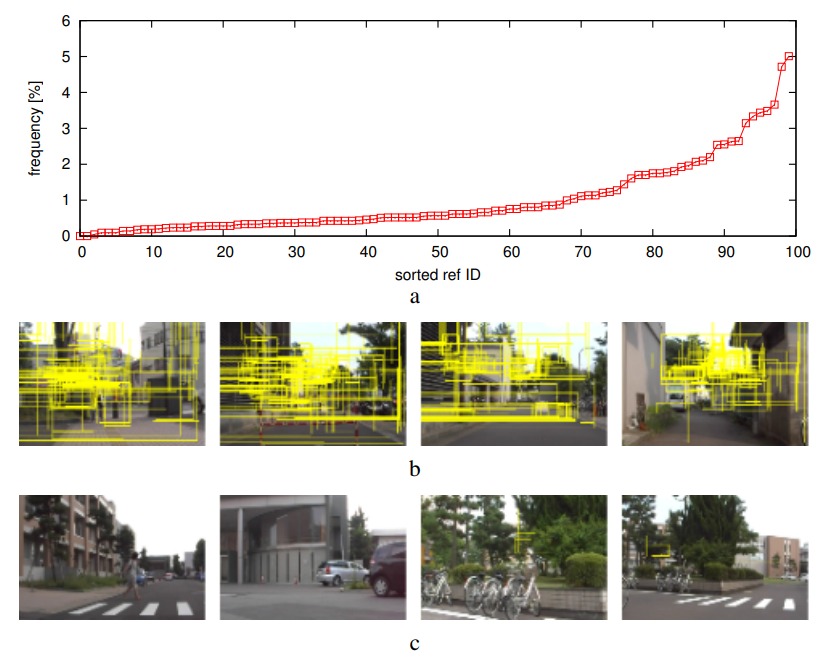
Fig. 9. Example results of selecting reference images. (a) Frequency of each reference image being selected. (b/c) The four most / least frequent reference images overlaid
with all the bounding boxes.
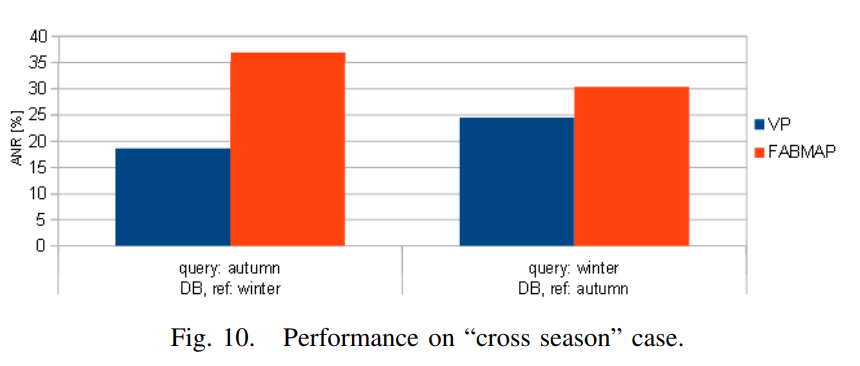
Fig. 10. Performance on “cross season” case.